eScriptorium
Daniel Stoekl
Directeur d’Etudes at the EPHE (daniel.stoekl@ephe.psl.eu)
eScriptorium is an open source platform to automatically transcribe manuscripts, printed works or inscriptions. It is developed by members of the AOrOc laboratory at the EPHE, PSL in Paris France. It works particularly well on documents in Hebrew script, but in principle, eScriptorium is script- and language agnostic: It can be trained to cope with almost any script, language or document. Usually this process involves the creation of a verified data set to train artificial neural networks to adapt to a specific layout type, handwriting and / or printed font. This process is similar to training a cellphone to adapt to your voice / language so that you can dictate SMS.
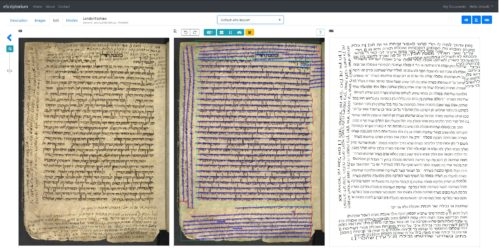
Document layouts can differ vastly. A fragment of a Qumran scroll is quite different from a letter from the Genizah, from a medieval codex with a central text surrounded by commentaries or from a Biblical polyglot. A dictionary has little in common with a newspaper, a scientific edition of a text or a journal article. Also, different researchers use the same document in different ways: Some only want the main text. Others only want the marginal commentary. Therefore, the computer needs to be trained to understand their structure in the way you want it to analyse it.

Handwriting and printed fonts can be extremely different, too. We are particularly advanced with regard to Hebrew script of medieval manuscripts where we have generalized models that perform well even without necessitating retraining for a new handwriting, including Aramaic, Judeo-Arabic and other languages written in Hebrew script. The generalized models work out of the box for medieval manuscripts in Ashkenazy, Italian and Sephardic square scripts and for some printed types. And we are actively training new models for other script types and richer language coverage, in particular Oriental and the various semi-square and some cursive. Here, too, the computer can be trained to adapt to your transcription conventions, e.g. with regard to interpunctuation, ligatures, allographs.
Beyond the sheer possibility of mass transcription, the preservation of the link between text and image is essential for facsimile editions or paleographical studies. We have also used eScriptorium to align existing transcriptions with the images for paleographical purposes. You can also train the computer to cut out all illuminations, drawings or tables, etc. Among the many projects using eScriptorium on different objects and scripts, let us mention here HTR4PGP, Minhag Italia, openITI, Sofer Mahir, Tikkoun Sofrimm SQE on large amounts of handwritten and printed texts in Hebrew and Arabic scripts, Dead Sea and Genizah fragments, medieval codexes and books. E.g. The data created in Sinai Rusinek’s DiJest project has permitted us to train basic general models for Hebrew print.
Creating the data for training require different amounts of time depending on the complexity of the dataset. We have used our creativity to develop an interface as simple and ergonomic as possible which is still capable to deal with simple and complex documents. Some of these videos may give you an impression. Basic descriptions can be found here and a different one here (in French). Real understanding of the process and the interface will in most cases require joining a life tutorial followed by hands-on practice to memorize buttons and mouse-movements.
We are offering a first tutorial for EAJS members and their students on how to use eScriptorium specifically for Hebrew script on Friday, December 17, 2021, between 9 am and 1 pm CET (via zoom). A second will be offered on Thursday, January 13, 2022, between 9 am and 1 pm CET (also via zoom). A third will be offered on Thursday, February 3, 2022, between 12h30 pm and 4h30 pm. Places are limited so please sign up here.
Furthermore, during the next year we will also offer to run our instance of eScriptorium on Hebrew script manuscripts of your choice and give you back the rough automatic transcription with the possibility to correct it. Proposals can be made here (aiming for one manuscript per week). You need to either have the images on your system or provide a iiif-link. We prefer to begin with manuscripts with simple layout that have never been transcribed or manuscripts for which you already have an e-text.
Finally, we are also looking for people that would like to join efforts to deal with complex layout print documents to create open-source segmentation models. If you are interested, please contact Daniel Stoekl directly via email.
Unlike other automatic transcription platforms, our interface and AI code is fully open source. This makes it easy to integrate it into pipelines by other projects or to modify the code. eScriptorium’s code can be found here. We also have a blog with news, more videos and a list of publications. Anyone can install eScriptorium on a linux or MAC system to work on personal documents but it makes much more sense to install it on a server with gpus (to speed up training) and with a good internet connection (that allows collaborative work). eScriptorium is free of charge if you install it yourself or have access to a shared instance. There are now many running instances in the world, among others in Paris, Heidelberg, Geneva, Haifa, College Park (MD). We however have no connection to the British website www.escriptorium.co.uk.
We graciously acknowledge that our work has been funded generously by the Scripta-PSL, Resilience H2020 and Biblissima+ Equipex, openITI Mellon and LectauRep ANF-Inria projects as well as the DIM STCN of the Région Ile-de-France. Advancements on Hebrew script have been possible thanks to support by the Rothschild Foundation Hanadiv Europe, the PHC Maimonide France-Israel, and Princeton University.